
Voor genealogisch onderzoek maken we veel gebruik van bronnen van voor het digitale tijdperk. Aangezien we nu in de 21e eeuw leven en gewend zijn geraakt aan het zoeken in databases en willen we dit graag ook toepassen op de teksten uit gedrukte bronnen. Hiervoor is een technologie ontwikkelt onder de naam Optical Character Recognition (OCR) dat alleen op gedrukte tekst toegepast kan worden.
Voordat OCR gebruikt kan worden moet er eerst een foto of scan gemaakt worden van een pagina uit een boek of krant. Software (computerprogramma) gaat vervolgens OCR toepassen op de eerder gemaakte afbeelding. Hierbij zoekt de software naar alle tekens in de afbeelding en zet deze vervolgens om naar leesbare tekens, daarmee wordt de afbeelding doorzoekbaar.
Doorgaans zit er geen spelling- of grammaticacontrole op, teken voor teken wordt geïdentificeerd. We verwachten letters en daarmee namen als resultaat. Om uiteenlopende redenen kan dit fout gaan en niet slechts bij enkele letters.
Laten we enkele redenen noemen:
- De tekst staat scheef
- De inkt is uitgelopen
- De inkt is niet evenredig verdeeld over de letter
- Er zit een vouw in de pagina
- De letters in een regel staan niet netjes op één lijn
- Het papier is verkreukeld
- Er zit een (water)vlek op het papier
- De onderliggende tekst is zichtbaar
- Etc., teveel om op te noemen
Met andere woorden het resultaat kan per pagina bijzonder uiteenlopend zijn. De ene pagina kan voor 90% correct omgezet zijn, de andere pagina slechts voor 40%. 100% is een utopie. Kan dit verbeterd worden? Jazeker. Door woord voor woord het resultaat te controleren en deze te corrigeren indien nodig. U begrijpt dat dit alleen al voor één krant niet realistisch is. Het komt er soms bijna op neer dat iemand een volledig boek aan het overtypen is omdat de toepassing van OCR niet het gewenste resultaat heeft gegeven. Nagenoeg geen enkel archief of organisatie waagt zich hieraan vanwege de benodigde tijd en daarmee hoge arbeidskosten.
Overigens behalen we met onze BRP’s een beter en stabieler resultaat dan OCR. BRP’s zijn 99% correct omdat deze door vrijwilligers worden overgetypt van geschreven teksten. Waarom geen 100%? Omdat er soms een meningsverschil is tussen twee onderzoekers omtrent de identificatie van een letter, het handschrift is zo onleesbaar dat niemand eruit komt of de letter is te beschadigd om geïdentificeerd te kunnen worden. Daarnaast bouwen onze vrijwilligers ervaring op en kunnen logica toepassen. Mens (oog) versus machine (OCR), mens wint.
Wat is nu het verschil met tekst in bijvoorbeeld Word? Het antwoord is eenvoudig, de tekst in Word is al digitaal. Zoals eerder gezegd wordt OCR op foto’s of scans van gedrukte tekst toegepast om deze te digitaliseren. Nadat OCR zijn werk heeft gedaan, dan pas is het digitaal terwijl tekst in Word dat al direct is bij het intypen.
Kunnen wij hier als vereniging iets aan doen? Nee helaas niet, we zijn geen softwareontwikkelaars. We kunnen het leven alleen gemakkelijker te maken door afbeeldingen van teksten zo goed mogelijk doorzoekbaar te maken.
Een praktisch voorbeeld
Delpher heeft als voordeel dat er onder water gekeken kan worden. Met andere woorden per artikel is te zien wat OCR als resultaat terug geeft.
Laten we als voorbeeld het volgende bericht nemen. Dit bericht heeft betrekking op de burgerlijke stand te Padang en staat in de Sumatra-courant : nieuws- en advertentieblad van 05-01-1870.

De OCR van Delpher heeft het omgezet in de volgende leesbare tekens.
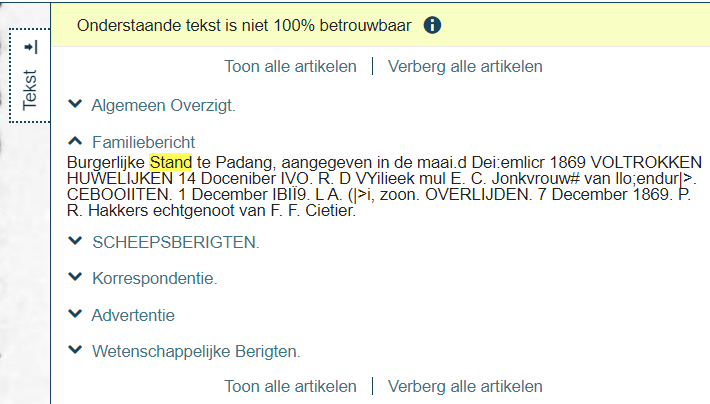
Tenzij u als zoeksleutel de familienaam Hakkers heeft opgegeven zult u dit krantenartikel nooit vinden. En laat hier nu net de door u zo vurig gewenste informatie staan over R.S. Reijnst, de ontbrekende schakel in uw onderzoek. Helaas u zult het niet vinden door middel van het zoekscherm.
In de praktijk komt het er toch op neer dat u ouderwets zelf de gehele tekst zult moeten lezen om echt niets te missen. OCR is een hulpmiddel en nog verre van perfect.
Onder water kijken Delpher
Als u een krant, boek of tijdschrift heeft geopend dan staat er aan de rechterkant op het scherm een klein balkje “Tekst” waar u op kunt klikken. Als deze niet zichtbaar is, even met uw muis bewegen over het medium.

